The empirical basis for the research is formed by the set of the Times newspaper issues of 1995 and the Guardian issues of 2000, 2005, 2010, 2013 and 2015 years.
The part of the research that is reflected on this website covers the following themes: key words and collocations, description of the most stable political vocabulary (the core) and political vocabulary that alters through time (the periphery), creation of the network of textual links and thematic clusters definition.
How key words of the political corpus are defined?
How key words of the political corpus are defined?
First of all, it is important to point out that keywords of political dictionary do not represent only political terms, on the contrary they cover a wide range of themes like social politics, education and so on and even general vocabulary and grammar structures. Most importantly this vocabulary occurs fore frequently in political texts that in any other kind of texts.
The following formula was used to define keywords for political subcorpora:
where f is observed frequency and m is mathematical expectation.
The formula, introduced by Anatoly Shaikevich, is a modification of a measure, based on Poisson’s law.
Example (using the Times):
Political subcorpus contains 2 973 091 words of text. The corpus of the newspaper contains 35244 153 words of text. That makes political subcorpus 0,084357 of the initial corpus (p=0,084357).
The frequency (F) of the word TORY in the initial corpus is 7929. To get the mathematical expectation we should apply the following formula:
That is to say, we expect the word TORY to occur in the political subcorpus about 668 times. As a matter of fact, the frequency (f) of the word in the political subcorpus is 5267. As we can see, the deviation of the mathematical expectation from the observed frequency is very high. Applying formula (1), we get:
Occurrences with S values higher than 3 should be considered as nonrandom and valuable for future analysis of the corpora.
How are collocations defined?
Similarly we to key words we define collocations. The same formula (1) is used for this purpose.
Example (using the Guardian):
Political corpus of the Guardian newspaper comprises 4 651 818 word forms.
Frequency (F) of PRIME MINISTER in political corpus is 3953, frequency of the word PRIME (F1) is 4892 and frequency of the word MINISTER (F2) is 7105.
Let’s figure out probability (p1) of the occurrence of the word PRIME in political corpus:
p1 = 4892/4651818 ≈ 0,001052
Then let’s calculate mathematical expectation of the occurrence of the expression PRIME MINISTER in newspaper’s political corpus:
Then using formula (1) we estimate S:
As probabilities of separate words are very small and probabilities of a combination of words are even smaller S value increases extremely that is why we find the logarithm of it (and use this value later for analysis):
ln(S) = 7,274514
What do we call core vocabulary and periphery vocabulary?
Core vocabulary is diachronically stable (keeps showing though many years).
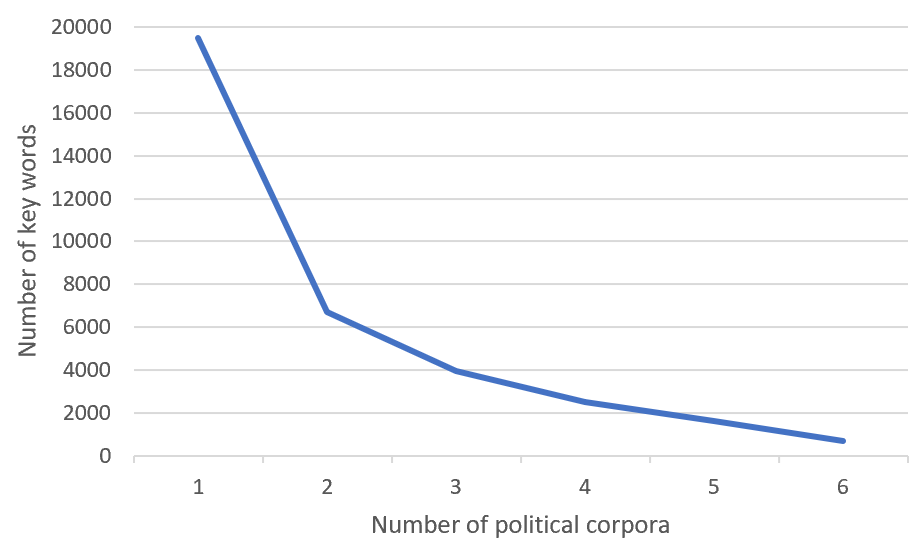
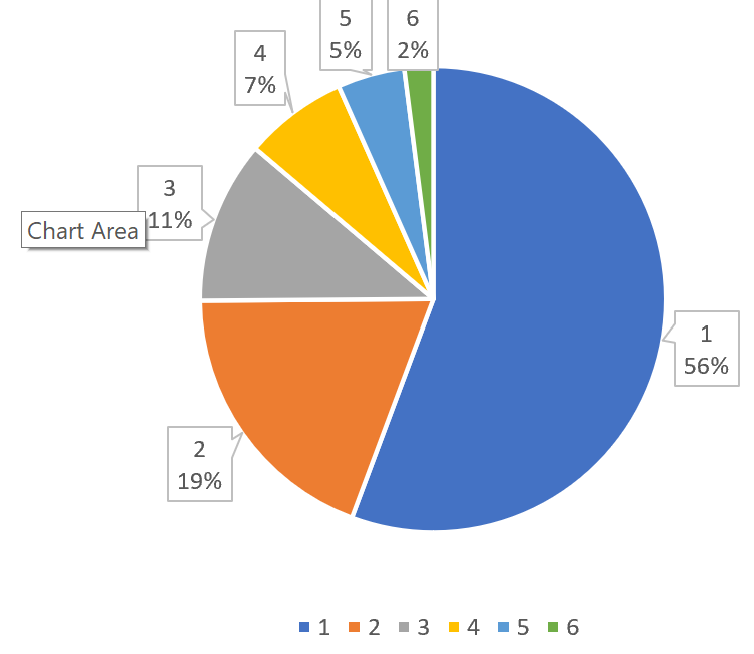
We believe that key words that occur at least at 3 different years could be considered stable thus included into core vocabulary.
As you can see below only a small amount of key words occur in 4,5 and 6 years simultaneously.
All other key words could be referred to as a periphery of political vocabulary.
Algorithm for network of textual links
Network of textual links is a very interesting tool that shows how all words in political corpus are connected with each other. As for the algorithm, the text is divided into pieces of 50 words (one piece is one index), and after that we use the same formula and count how many times two words cooccur together in one index. The Guardian newspaper of 2015 has 82 650 indexes (N = 82650).
Example:
Frequency (f) CUT BUDGET = 530
Frequency (f1) CUT =4117
Frequency (f2) BUDGET =1981.
Mathematical expectation of these 2 words to meet in one index (m):
Thus, we expect that words CUT and BUDGET will cooccur 98 times in one index.
In reality they cooccur together 530 times.
We use the same formula to demonstrate that difference in one value S:
The final network comprises more than 600000 connections with S ≥3. This is a huge network that cannot be visualised with existing graph instruments. A small part of the network of 8000 connections can be explored here.
Finding clusters
The existing network forms many thematical clusters. We offer the following algorithm for automatic identification of clusters. The algorithm states that we should find a minimal cluster first – the one that combines 3 connections f.e.: voting system; system first-past-the-post; first-past-the-post voting.
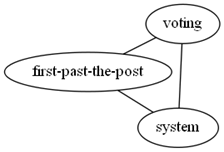
The larger clusters are built around minimal clusters. The current network allows us to identify more than 2330 clusters: from minimal clusters to large ones with more than 2800 connections (≈150 words).
Clusters could be combined if they share many common connections.
Some large clusters for investigation from the original network with stable pares of words
(the ones that cooccur in 4 or 5 years and value of S≥3).
Peer-reviewed articles:
THE CENTRE AND THE PERIPHERY OF THE POLITICAL VOCABULARY OF A NEWSPAPER (BASED ON THE BRITISH NEWSPAPERS “THE TIMES” AND “THE GUARDIAN”)
Political linguistics · Oct 18, 2016
The purpose of this research is to describe the political vocabulary of a newspaper. The topicality of the research is determined by the specificity of the print mass media: the newspapers remain the most important environment where political texts circulate, which are not only the reflection of political events but the tools of politics as well. The scientific approach applied in this research is determined by the corpus of texts and is based primarily on the quantitative procedures. The newspapers “The Times” published in 1995 and “The Guardian” (2000, 2005, 2010, 2013, 2015) are the empirical basis of the research. The frequency vocabulary and the political subcorpus were made, which contained the headings connected with politics, functional marks of the authors’ names were taken into account as
well. The formula of determining the keywords of the newspaper discourse of the certain period is offered. The most stable units of the political vocabulary of a newspaper (frequent in all the newspapers) refer to the nucleus of the political vocabulary of a newspaper. The words used in four or five sub-corpora, included in the centre of political lexicon, do not differ semantically or grammatically from the keywords from the nucleus of the political vocabulary. The rest of the keywords refer to the periphery of the political vocabulary of a newspaper. The keywords of the political vocabulary of a newspaper are divided into several groups (connected with the government, ideological abstracts, connected with the elections and votes, concerned with the social politics, elements of the economic policy).
KEYWORDS: political discourse; political text; mass media discourse; political vocabulary, text corpus; keyword; periphery of the political vocabulary
SEARCH FOR CLUSTERS IN A NETWORK OF TEXTUAL LINKS OF WORDS
PROCEEDINGS OF THE INTERNATIONAL CONFERENCE «CORPUS LINGUISTICS–2017» · Jun 27, 2017
The paper is based on the corpus of political articles of the Guardian newspaper of 5 years
(16,6 million word tokens). For the purpose of the corpus analysis, the network of textual links of
words is created using comparison of expected and observed frequency of co-occurrences of each
pair of words. The size of the received network is huge (more than half a million of links), which
compels us to seek ways of defining clusters. Clusterization starts with connecting three interrelated
pairs of words (triplets). Under the approach 2330 clusters were identified.
BLOG VOCABULARY IN POLITICAL NEWSPAPER (BASED ON THE GUARDIAN)
Political Linguistics · Oct 6, 2017
Article analyzes the language of political blogs on the web site of The Guardian. Political blogs are one of the sections of the newspaper, but they are published only on the Internet. One of the interesting differences of a political blog from traditional newspaper texts is the possibility to publish full versions of candidates’ addresses, speeches of political leaders, unabridged interviews, etc. The advantage of the on-line version is the possibility of “live” communication with the readers, and the existence of the platform for such communication. This research describes the vocabulary of political blogs and lists the stylistic and issue-related differences between the words of political blogs and those of newspaper. The material for this research is made of the issues of The Guardian published in 2008 – 2013
(around 58 mln. words). To reach the goals we used the method of keywords identification for the sub-corpus of texts included in the larger corpus; it was described by A.Ya. Shaikevich. Blogs are very perceptive to the newsbreaks. Breaking news make some words keywords for this or that sub-corpus. It is very seldom that blogs may form agenda, they just discuss the topic covered in the media. The vocabulary of blogs coincides with the vocabulary of political newspaper (basic political terms words that describe parliamentary functions, voting procedure, etc.). The topic-related and stylistic peculiarities of political blogs include emotionally colored words, quotations, argumentation, colloquial words, shortenings and abbreviations.
KEYWORDS: political blogs; journalism; mass media; media discourse; newspaper vocabulary; corpus linguistics; linguo-statistics.
Also please find below several scientific works on distributional statistical analysis of texts by Anatoly Shaikevich (the author of the methodology I used while analyzing political newspaper discourse wikipedia). The first one is in English and the others are in Russian.
https://www.jbe-platform.com/content/journals/10.1075/ijcl.6.2.03sha
This paper draws attention to the complexity of problems arising in statistical linguistics when it must compare various corpora. Those problems are discussed from the point of view of distributional statistical analysis of texts; that is, a set of formal procedures with a minimum of preconceived linguistic knowledge. The terminological distinction between contrastive and comparable corpora is introduced.
Shaykevich A. Ya., Andryushchenko V. M., Rebetskaya N. A. Distributional statistical analysis of Russian prose 1850— 1870 years, Volumes 1,2,3
https://www.labirint.ru/authors/67786/
Shaykevich A. Ya. Distributivno-statisticheskiy analiz v semantike // Printsipy i metody semanticheskikh issledovaniy. p.353 M., 1976.